

O Google revelou seu mais recente modelo de IA, o Gemini 1.5, que apresenta o que a empresa chama de uma janela de contexto de um milhão de tokens “experimental”.
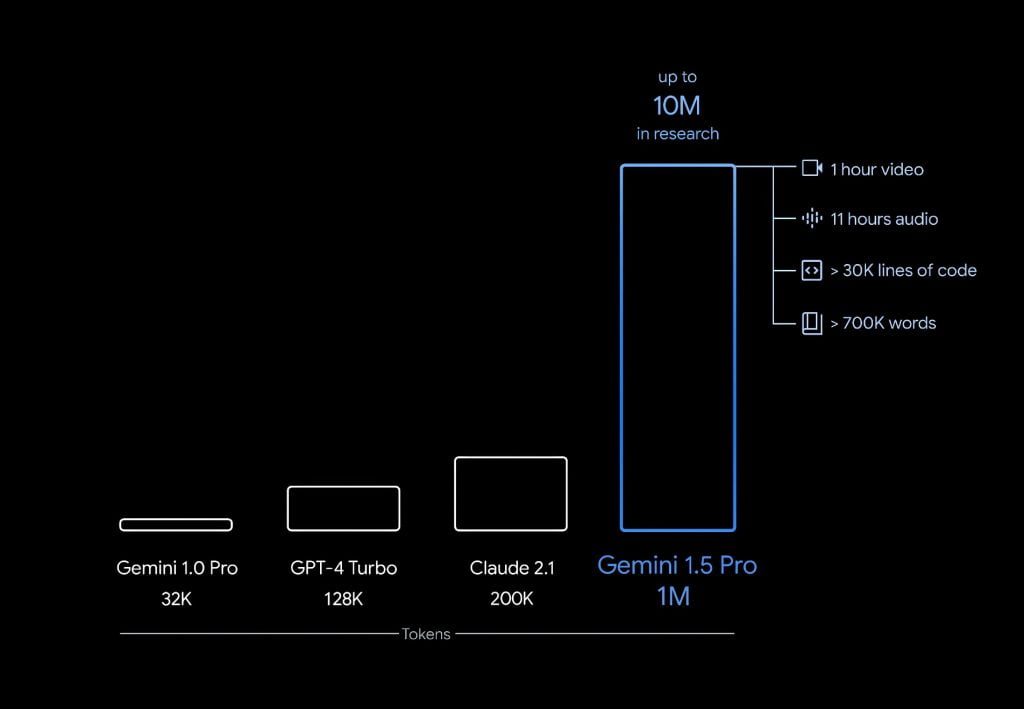
A nova capacidade permite que o Gemini 1.5 processe passagens de texto extremamente longas – até um milhão de caracteres – para entender o contexto e o significado. Isso supera sistemas de IA anteriores como o Claude 2.1 e o GPT-4 Turbo, que têm no máximo 200.000 e 128.000 tokens, respectivamente.
“O Gemini 1.5 Pro alcança uma recordação quase perfeita em tarefas de recuperação de contexto longo em várias modalidades, melhora o estado da arte em QA de documentos longos, QA de vídeos longos e ASR de contexto longo, e iguala ou supera o desempenho de última geração do Gemini 1.0 Ultra em um amplo conjunto de benchmarks”, disseram pesquisadores do Google em um artigo técnico.
A eficiência do modelo mais recente do Google é atribuída à sua arquitetura inovadora de Mixture-of-Experts (MoE).
“Enquanto um Transformer tradicional funciona como uma grande rede neural, modelos MoE são divididos em redes neurais ‘especialistas’ menores”, explicou Demis Hassabis, CEO do Google DeepMind.
“Dependendo do tipo de entrada fornecida, os modelos MoE aprendem a ativar seletivamente apenas os caminhos de especialistas mais relevantes em sua rede neural. Essa especialização melhora massivamente a eficiência do modelo.”
Para demonstrar o poder da janela de contexto de 1 milhão de tokens, o Google mostrou como o Gemini 1.5 poderia processar todo o transcrito de voo Apollo 11, com 326.914 tokens, e depois responder com precisão a perguntas específicas sobre ele. Também resumiu detalhes importantes de um filme silencioso com 684.000 tokens quando solicitado.

Inicialmente, o Google está fornecendo acesso gratuito a uma prévia limitada do Gemini 1.5 para desenvolvedores e empresas, com uma janela de contexto de um milhão de tokens. Um lançamento geral com 128.000 tokens para o público virá posteriormente, juntamente com detalhes de preços.



